Building Client Libraries
NSQ’s design pushes a lot of responsibility onto client libraries in order to maintain overall cluster robustness and performance.
This guide attempts to outline the various responsibilities well-behaved client libraries need to
fulfill. Because publishing to nsqd is trivial (just an HTTP POST to the /pub endpoint), this
document focuses on consumers.
By setting these expectations we hope to provide a foundation for achieving consistency across languages for NSQ users.
Overview
- Configuration
- Discovery (optional)
- Connection Handling
- Feature Negotiation
- Data Flow / Heartbeats
- Message Handling
- RDY State
- Backoff
- Encryption/Compression
Configuration
At a high level, our philosophy with respect to configuration is to design the system to have the flexibility to support different workloads, use sane defaults that run well “out of the box”, and minimize the number of dials.
A consumer subscribes to a topic on a channel over a TCP connection to nsqd instance(s). You
can only subscribe to one topic per connection so multiple topic consumption needs to be structured
accordingly.
Using nsqlookupd for discovery is optional so client libraries should support a configuration
where a consumer connects directly to one or more nsqd instances or where it is configured to
poll one or more nsqlookupd instances. When a consumer is configured to poll nsqlookupd the
polling interval should be configurable. Additionally, because typical deployments of NSQ are in
distributed environments with many producers and consumers, the client library should automatically
add jitter based on a random % of the configured value. This will help avoid a thundering herd of
connections. For more detail see Discovery.
An important performance knob for consumers is the number of messages it can receive before nsqd
expects a response. This pipelining facilitates buffered, batched, and asynchronous message
handling. By convention this value is called max_in_flight and it effects how RDY state is
managed. For more detail see RDY State.
Being a system that is designed to gracefully handle failure, client libraries are expected to implement retry handling for failed messages and provide options for bounding that behavior in terms of number of attempts per message. For more detail see Message Handling.
Relatedly, when message processing fails, the client library is expected to automatically handle
re-queueing the message. NSQ supports sending a delay along with the REQ command. Client
libraries are expected to provide options for what this delay should be set to initially (for the
first failure) and how it should change for subsequent failures. For more detail see
Backoff.
Most importantly, the client library should support some method of configuring callback handlers for message processing. The signature of these callbacks should be simple, typically accepting a single parameter (an instance of a “message object”).
Discovery
An important component of NSQ is nsqlookupd, which provides a discovery service for consumers to
locate the nsqd that provide a given topic at runtime.
Although optional, using nsqlookupd greatly reduces the amount of configuration required to
maintain and scale a large distributed NSQ cluster.
When a consumer uses nsqlookupd for discovery, the client library should manage the process of
polling all nsqlookupd instances for an up-to-date set of nsqd providing the topic in question,
and should manage the connections to those nsqd.
Querying an nsqlookupd instance is straightforward. Perform an HTTP request to the lookup
endpoint with a query parameter of the topic the consumer is attempting to discover (i.e.
/lookup?topic=clicks). The response format is JSON:
{
"channels": ["archive", "science", "metrics"],
"producers": [
{
"broadcast_address": "clicksapi01.routable.domain.net",
"hostname": "clicksapi01.domain.net",
"remote_address": "172.31.27.114:51996",
"tcp_port": 4150,
"http_port": 4151,
"version": "1.0.0-compat"
},
{
"broadcast_address": "clicksapi02.routable.domain.net",
"hostname": "clicksapi02.domain.net",
"remote_address": "172.31.34.29:14340",
"tcp_port": 4150,
"http_port": 4151,
"version": "1.0.0-compat"
}
]
}The broadcast_address and tcp_port should be used to connect to an nsqd. Because, by design,
nsqlookupd instances don’t share or coordinate their data, the client library should union the
lists it received from all nsqlookupd queries to build the final list of nsqd to connect to.
The broadcast_address:tcp_port combination should be used as the unique key for this union.
A periodic timer should be used to repeatedly poll the configured nsqlookupd so that consumers
will automatically discover new nsqd. The client library should automatically initiate
connections to all newly discovered instances.
When client library execution begins it should bootstrap this polling process by kicking off an
initial set of requests to the configured nsqlookupd instances.
Connection Handling
Once a consumer has an nsqd to connect to (via discovery or manual configuration), it should open
a TCP connection to broadcast_address:port. A separate TCP connection should be made to each
nsqd for each topic the consumer wants to subscribe to.
When connecting to an nsqd instance, the client library should send the following data, in order:
- the magic identifier
- an
IDENTIFYcommand (and payload) and read/verify response (see Feature Negotiation) - a
SUBcommand (specifying desired topic) and read/verify response - an initial
RDYcount of 1 (see RDY State).
(low-level details on the protocol are available in the spec)
Reconnection
Client libraries should automatically handle reconnection as follows:
-
If the consumer is configured with a specific list of
nsqdinstances, reconnection should be handled by delaying the retry attempt in an exponential backoff manner (i.e. try to reconnect in 8s, 16s, 32s, etc., up to a max). -
If the consumer is configured to discover instances via
nsqlookupd, reconnection should be handled automatically based on the polling interval (i.e. if a consumer disconnects from annsqd, the client library should only attempt to reconnect if that instance is discovered by a subsequentnsqlookupdpolling round). This ensures that consumers can learn aboutnsqdthat are introduced to the topology and ones that are removed (or failed).
Feature Negotiation
The IDENTIFY command can be used to set nsqd side metadata, modify client settings,
and negotiate features. It satisfies two needs:
- In certain cases a client would like to modify how
nsqdinteracts with it (such as modifying a client’s heartbeat interval and enabling compression, TLS, output buffering, etc. - for a complete list see the spec) nsqdresponds to theIDENTIFYcommand with a JSON payload that includes important server side configuration values that the client should respect while interacting with the instance.
After connecting, based on the user’s configuration, a client library should send an IDENTIFY
command, the body of which is a JSON payload:
{
"client_id": "metrics_increment",
"hostname": "app01.bitly.net",
"heartbeat_interval": 30000,
"feature_negotiation": true
}The feature_negotiation field indicates that the client can accept a JSON payload in return.
The client_id and hostname are arbitrary text fields that are used by nsqd (and nsqadmin)
to identify clients. heartbeat_interval configures the interval between heartbeats on a
per-client basis.
The nsqd will respond OK if it does not support feature negotiation (introduced in nsqd
v0.2.20+), otherwise:
{
"max_rdy_count": 2500,
"version": "0.2.20-alpha"
}More detail on the use of the max_rdy_count field is in the RDY State section.
Data Flow and Heartbeats
Once a consumer is in a subscribed state, data flow in the NSQ protocol is asynchronous. For consumers, this means that in order to build truly robust and performant client libraries they should be structured using asynchronous network IO loops and/or “threads” (the scare quotes are used to represent both OS-level threads and userland threads, like coroutines).
Additionally clients are expected to respond to periodic heartbeats from the nsqd instances
they’re connected to. By default this happens at 30 second intervals. The client can respond with
any command but, by convention, it’s easiest to simply respond with a NOP whenever a heartbeat
is received. See the protocol spec for specifics on how to identify heartbeats.
A “thread” should be dedicated to reading data off the TCP socket, unpacking the data from the frame, and performing the multiplexing logic to route the data as appropriate. This is also conveniently the best spot to handle heartbeats. At the lowest level, reading the protocol involves the following sequential steps:
- read 4 byte big endian uint32 size
- read size bytes data
- unpack data
- …
- profit
- goto 1
A Brief Interlude on Errors
Due to their asynchronous nature, it would take a bit of extra state tracking in order to
correlate protocol errors with the commands that generated them. Instead, we took the “fail fast”
approach so the overwhelming majority of protocol-level error handling is fatal. This means that if
the client sends an invalid command (or gets itself into an invalid state) the nsqd instance it’s
connected to will protect itself (and the system) by forcibly closing the connection (and, if
possible, sending an error to the client). This, coupled with the connection handling mentioned
above, makes for a more robust and stable system.
The only errors that are not fatal are:
E_FIN_FAILED- aFINcommand for an invalid message IDE_REQ_FAILED- aREQcommand for an invalid message IDE_TOUCH_FAILED- aTOUCHcommand for an invalid message ID
Because these errors are most often timing issues, they are not considered fatal. These situations
typically occur when a message times out on the nsqd side and is re-queued and delivered to
another consumer. The original recipient is no longer allowed to respond on behalf of that message.
Message Handling
When the IO loop unpacks a data frame containing a message, it should route that message to the configured handler for processing.
The sending nsqd expects to receive a reply within its configured message timeout (default: 60
seconds). There are a few possible scenarios:
- The handler indicates that the message was processed successfully.
- The handler indicates that the message processing was unsuccessful.
- The handler decides that it needs more time to process the message.
- The in-flight timeout expires and
nsqdautomatically re-queues the message.
In the first 3 cases, the client library should send the appropriate command on the consumer’s
behalf (FIN, REQ, and TOUCH respectively).
The FIN command is the simplest of the bunch. It tells nsqd that it can safely discard the
message. FIN can also be used to discard a message that you do not want to process or retry.
The REQ command tells nsqd that the message should be re-queued (with an optional parameter
specifying the amount of time to defer additional attempts). If the optional parameter is not
specified by the consumer, the client library should automatically calculate the duration in
relation to the number of attempts to process the message (a multiple is typically sufficient). The
client library should discard messages that exceed the configured max attempts. When this occurs, a
user-supplied callback should be executed to notify and enable special handling.
If the message handler requires more time than the configured message timeout, the TOUCH command
can be used to reset the timer on the nsqd side. This can be done repeatedly until the message is
either FIN or REQ, up to the sending nsqd’s configured max_msg_timeout. Client libraries
should never automatically TOUCH on behalf of the consumer.
If the sending nsqd instance receives no response, the message will time out and be
automatically re-queued for delivery to an available consumer.
Finally, a property of each message is the number of attempts. Client libraries should compare this value against the configured max and discard messages that have exceeded it. When a message is discarded there should be a callback fired. Typical default implementations of this callback might include writing to a directory on disk, logging, etc. The user should be able to override the default handling.
RDY State
Because messages are pushed from nsqd to consumers we needed a way to manage the flow of data in
user-land rather than relying on low-level TCP semantics. A consumer’s RDY state is NSQ’s flow
control mechanism.
As outlined in the configuration section, a consumer is configured with a
max_in_flight. This is a concurrency and performance knob, e.g. some downstream systems are able
to more-easily batch process messages and benefit greatly from a higher max-in-flight.
When a consumer connects to nsqd (and subscribes) it is placed in an initial RDY state of 0.
No messages will be delivered.
Client libraries have a few responsibilities:
- bootstrap and evenly distribute the configured
max_in_flightto all connections. - never allow the aggregate sum of
RDYcounts for all connections (total_rdy_count) to exceed the configuredmax_in_flight. - never exceed the per connection
nsqdconfiguredmax_rdy_count. - expose an API method to reliably indicate message flow starvation
1. Bootstrap and Distribution
There are a few considerations when choosing an appropriate RDY count for a connection (in order
to evenly distribute max_in_flight):
- the # of connections is dynamic, often times not even known in advance (ie. when
discovering
nsqdviansqlookupd). max_in_flightmay be lower than your number of connections
To kickstart message flow a client library needs to send an initial RDY count. Because the
eventual number of connections is often not known ahead of time it should start with a value of 1
so that the client library does not unfairly favor the first connection(s).
Additionally, after each message is processed, the client library should evaluate whether or not
it’s time to update RDY state. An update should be triggered if the current value is 0 or if it
is below ~25% of the last value sent.
The client library should always attempt to evenly distribute RDY count across all connections.
Typically, this is implemented as max_in_flight / num_conns.
However, when max_in_flight < num_conns this simple formula isn’t sufficient. In this state,
client libraries should perform a dynamic runtime evaluation of connected nsqd “liveness” by
measuring the duration of time since it last received a message over a given connection. After a
configurable expiration, it should re-distribute whatever RDY count is available to a new
(random) set of nsqd. By doing this, you guarantee that you’ll (eventually) find nsqd with
messages. Clearly this has a latency impact.
2. Maintaining max_in_flight
The client library should maintain a ceiling for the maximum number of messages in flight for a
given consumer. Specifically, the aggregate sum of each connection’s RDY count should never exceed
the configured max_in_flight.
Below is example code in Python to determine whether or not the proposed RDY count is valid for a given connection:
def send_ready(reader, conn, count):
if (reader.total_ready_count + count) > reader.max_in_flight:
return
conn.send_ready(count)
conn.rdy_count = count
reader.total_ready_count += count3. nsqd Max RDY Count
Each nsqd is configurable with a --max-rdy-count (see feature
negotiation for more information on the handshake a consumer can perform to
ascertain this value). If the consumer sends a RDY count that is outside of the acceptable range
its connection will be forcefully closed. For backwards compatibility, this value should be assumed
to be 2500 if the nsqd instance does not support feature negotiation.
4. Message Flow Starvation
Finally, the client library should provide an API method to indicate message flow starvation. It is
insufficient for consumers (in their message handlers) to simply compare the number of messages they
have in-flight vs. their configured max_in_flight in order to decide to “process a batch”. There
are two cases when this is problematic:
- When consumers configure
max_in_flight > 1, due to variablenum_conns, there are cases wheremax_in_flightis not evenly divisible bynum_conns. Because the contract states that you should never exceedmax_in_flight, you must round down, and you end up with cases where the sum of allRDYcounts is less thanmax_in_flight. - Consider the case where only a subset of
nsqdhave messages. Because of the expected even distribution ofRDYcount, those activensqdonly have a fraction of the configuredmax_in_flight.
In both cases, a consumer will never actually receive max_in_flight # of messages. Therefore, the
client library should expose a method is_starved that will evaluate whether any of the
connections are starved, as follows:
def is_starved(conns):
for c in conns:
# the constant 0.85 is designed to *anticipate* starvation rather than wait for it
if c.in_flight > 0 and c.in_flight >= (c.last_ready * 0.85):
return True
return FalseThe is_starved method should be used by message handlers to reliably identify when to process a
batch of messages.
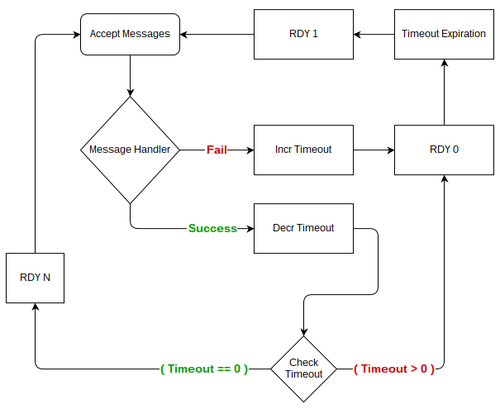
Backoff
The question of what to do when message processing fails is a complicated one to answer. The message handling section detailed client library behavior that would defer the processing of failed messages for some (increasing) duration of time. The other piece of the puzzle is whether or not to reduce throughput. The interplay between these two pieces of functionality is crucial for overall system stability.
By slowing down the rate of processing, or “backing off”, the consumer allows the downstream system to recover from transient failure. However, this behavior should be configurable as it isn’t always desirable, such as situations where latency is prioritized.
Backoff should be implemented by sending RDY 0 to the appropriate nsqd, stopping message
flow. The duration of time to remain in this state should be calculated based on the number of
repeated failures (exponential). Similarly, successful processing should reduce this duration until
the reader is no longer in a backoff state.
While a reader is in a backoff state, after the timeout expires, the client library should only ever
send RDY 1 regardless of max_in_flight. This effectively “tests the waters” before returning to
full throttle. Additionally, during a backoff timeout, the client library should ignore any success
or failure results with respect to calculating backoff duration (i.e. it should only take into
account one result per backoff timeout).
Encryption/Compression
NSQ supports encryption and/or compression feature negotiation via the IDENTIFY command. TLS is
used for encryption. Both Snappy and DEFLATE are supported for compression. Snappy is
available as a third-party library, but most languages have some native support for DEFLATE.
When the IDENTIFY response is received and you’ve requested TLS via the tls_v1 flag you’ll get
something similar to the following JSON:
{
"deflate": false,
"deflate_level": 0,
"max_deflate_level": 6,
"max_msg_timeout": 900000,
"max_rdy_count": 2500,
"msg_timeout": 60000,
"sample_rate": 0,
"snappy": true,
"tls_v1": true,
"version": "0.2.28"
}After confirming that tls_v1 is set to true (indicating that the server supports TLS), you
initiate the TLS handshake (done, for example, in Python using the ssl.wrap_socket call) before
anything else is sent or received on the wire. Immediately following a successful TLS handshake you
must read an encrypted NSQ OK response.
In a similar fashion, if you’ve enabled compression you’ll look for snappy or deflate being
true and then wrap the socket’s read and write calls with the appropriate (de)compressor. Again,
immediately read a compressed NSQ OK response.
These compression features are mutually-exclusive.
It’s very important that you either prevent buffering until you’ve finished negotiating encryption/compression, or make sure to take care to read-to-empty as you negotiate features
Bringing It All Together
Distributed systems are fun.
The interactions between the various components of an NSQ cluster work in concert to provide a platform on which to build robust, performant, and stable infrastructure. We hope this guide shed some light as to how important the client’s role is.
In terms of actually implementing all of this, we treat pynsq and go-nsq as our reference codebases. The structure of pynsq can be broken down into three core components:
-
Message- a high-level message object, which exposes stateful methods for responding tonsqd(FIN,REQ,TOUCH, etc.) as well as metadata such as attempts and timestamp. -
Connection- a high-level wrapper around a TCP connection to a specificnsqd, which has knowledge of in flight messages, itsRDYstate, negotiated features, and various timings. -
Consumer- the front-facing API a user interacts with, which handles discovery, creates connections (and subscribes), bootstraps and managesRDYstate, parses raw incoming data, createsMessageobjects, and dispatches messages to handlers. -
Producer- the front-facing API a user interacts with, which handles publishing.
We’re happy to help support anyone interested in building client libraries for NSQ. We’re looking for contributors to continue to expand our language support as well as flesh out functionality in existing libraries. The community has already open sourced many client libraries.